Our Research
Work at CCU centers around applications of machine learning and artificial intelligence to a wide variety of content. In particular, we have had a long history of basic and applied research on text-based data. A sampling of recent projects we have undertaken is given below. Most of these projects are related to learning with little to no labeled data, which has historically been another focus area in our group.
Detecting deepfake text
The rapid development of deepfake technologies poses significant issues and concerns vital to maintaining information integrity, including detecting and limiting the spread of deceptive or misleading information. Due to recent advances in natural language generation, algorithmically-generated text is now convincing enough to fool most non-experts. As these technologies improve and become nearly impossible to detect by humans, it is crucial to develop automated countermeasures. At ARL:UT, we have developed state-of-the-art detection capabilities for deepfake text content, and are continually building upon our capabilities to keep pace with current trends. For further information, please contact us.
To illustrate the difficulty in distinguishing between human-written and generated content in a variety of contexts, including scientific and technical writing, computer code, e-mails, web content, and news, we have created the ARL:UT Real or Deepfake App. This interactive tool contains both human-written and generated content from a variety of sources, and tangibly demonstrates the threats posed by deepfake text generated using readily available methods.

Example of biomedical text from the ARL:UT Real or Deepfake App.
Hypernym prediction
In joint work with the UT Austin Department of Linguistics and Department of Mathematics, we co-developed new methods for hypernym prediction. Hypernym prediction is the task of predicting more general concepts for a term ('IS-A' relation), and is an important building block for creating taxonomies and for enabling inferences for downstream tasks such as question answering and reading comprehension. Learning hypernymy is also important in practice, as knowing a word’s hypernyms gives an approximation of its meaning. Our proposed approach achieves state-of-the-art performance and outperforms the previous best approach for hypernym prediction. This work was published at the 2020 International Conference on Computational Linguistics (COLING), a major natural language processing conference.
Human-guided machine learning and safe imitation learning
Many machine learning applications require human guidance in order to safely learn and adapt to a wide variety of human preferences and goals. One common approach for reinforcement learning settings is imitation learning, where an autonomous agent learns to perform a task by observing demonstrations. As part of this process, it is important for the agent to be able to provide safety guarantees that ensure that it has accurately learned the intended behavior.
In joint work with the UT Austin Computer Science department, we co-developed a method called Bayesian Reward Extrapolation (Bayesian REX) that can be used to efficiently compute high-confidence bounds on policy performance, without access to samples of the demonstrator's reward function. Using human preferences over demonstrations, this method leverages deep neural function approximation along with self-supervised learning of reward features to compute a posterior distribution over reward functions. To our knowledge, it is the first to do so in a way that can be used for both fast Bayesian reward learning in high-dimensional, visual control tasks and for efficiently deriving high-confidence performance bounds. Bayesian REX can be used to rank the performance and risk of various evaluation policies and provide a way to detect reward hacking behaviors. This work was accepted and presented at the 2020 International Conference on Machine Learning (ICML).
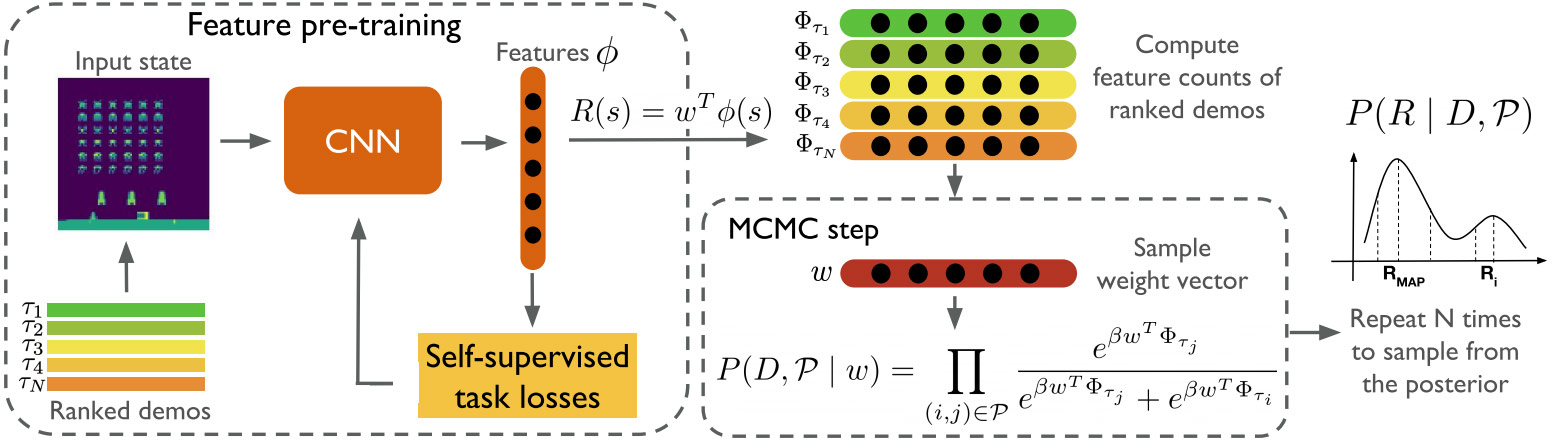
The Bayesian Reward Extrapolation (Bayesian REX) method. View larger image.
Transfer learning for entity recognition
In this project, we replicated and extended several past studies on transfer learning for entity recognition. In particular, we were interested in entity recognition problems where the class labels in the source and target domains are different. Our work was the first direct comparison of several previously published approaches in this problem setting. In addition, we performed experiments on seven new source/target corpus pairs, nearly doubling the total number of corpus pairs that had been studied in all past work combined. A paper based on this work received an Area Chair Favorites award at the 2018 International Conference on Computational Linguistics (COLING).
New techniques for network and topic modeling
In this joint project with the UT Austin Electrical and Computer Engineering Department, we created a new model for network and topic modeling based on matrix factorization. The resulting method, called Joint Gamma Process Poisson Factorization (J-GPPF), can simultaneously extract latent communities and topics from a dataset. This is illustrated in the following example, where we model 1,600 Wikipedia articles tagged with 'acoustic' and 'machine learning' categories. J-GPPF yields the following three topics, each given by their associated top words:
| Topic Number | Top 10 Words |
| 1st | learning, data, algorithm, machine, model, method, used, set, problem, function |
| 2nd | album, music, song, released, one, band, country, guitar, award, record |
| 3rd | sound, frequency, wave, acoustic, one, time, used, source, also, tone |
The method correctly finds a 'machine learning' topic as well as two separate topics related to 'acoustics', a musical-based one and a scientific-based one. Furthermore, it simultaneously identifies groups of Wikipedia categories within a category ontology network, shown in the following graph in terms of top words for the top groups:
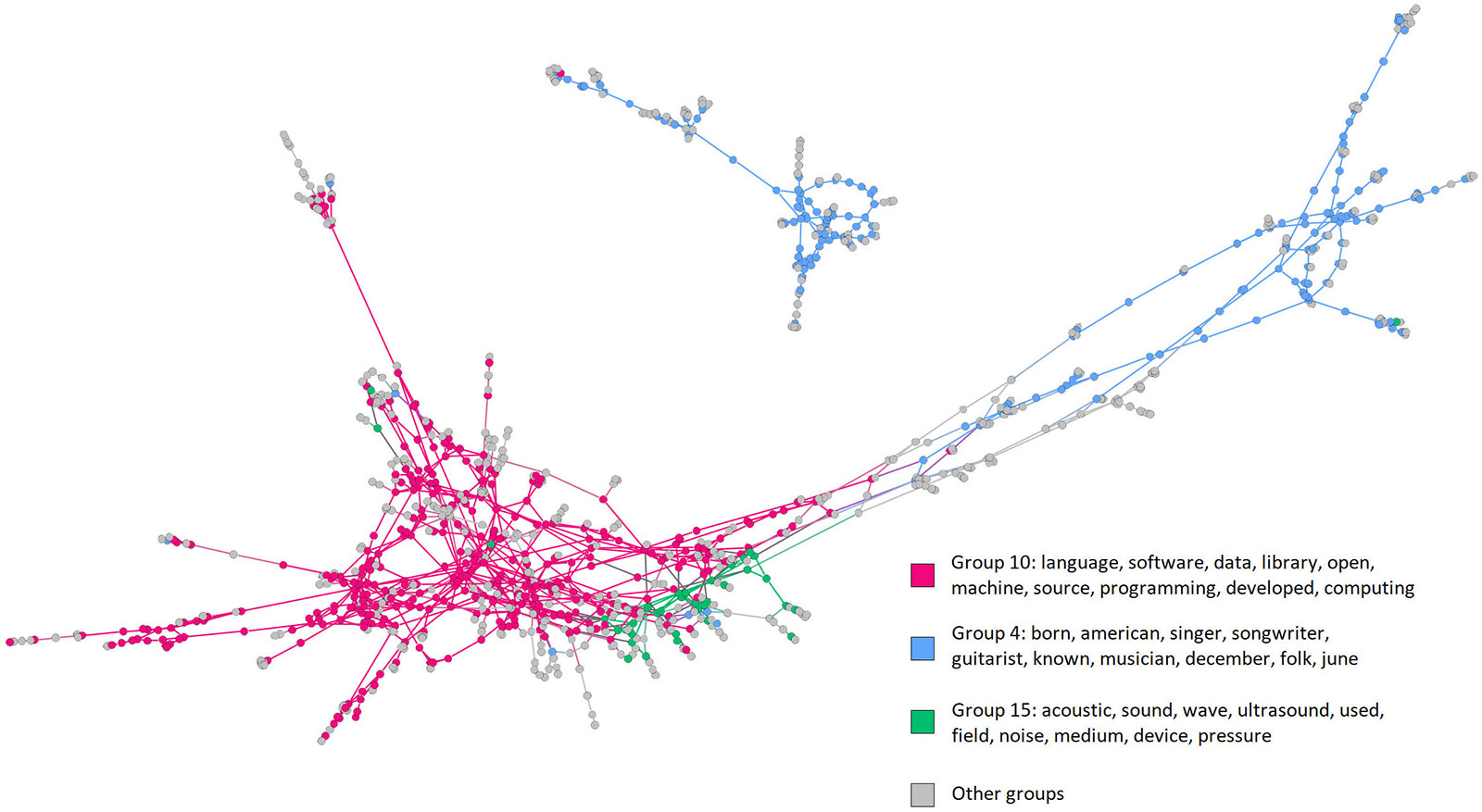
Groups of Wikipedia categories within a category ontology network. View larger image.
Computationally-optimized Scala code for J-GPPF is available, along with simplified Poisson factorization models for network-only or text-only corpora. This code is accompanied by a tutorial on joint factorizaton using a dataset consisting of historical voting records from the U.S. Senate. The J-GPPF model was originally published at the 2015 European Conference on Machine Learning and Data Mining (ECML PKDD).
